Speak Your Truth: Do LLMs Lie to Us?
Hopefully accessible explainer of recent CoT faithfulness research. Heavily inspired by Wait But Why, as well as the Siliconversations and Robert Miles AI Safety YouTube channels.
Do We Actually Understand AI?
Since ChatGPT took the world by storm in late 2022, AI has become the only thing anyone ever talks about. Is it overhyped? Underhyped? Hyped to an appropriate degree? Primed to take all of our jobs? A looming existential threat? There are no concrete answers, but regardless, it does look like AI is here to stay. The technology is increasingly being deployed in settings as diverse as the military, healthcare, and the justice system. You’d hope that someone out there has a pretty decent understanding of how it works.
Unfortunately, AI experts have repeatedly warned that our understanding of AI systems leaves a lot to be desired. This situation isn’t ideal. You probably don’t know the ins and outs of how a toaster works, but you trust that there’s some people in the world who actually did the hard work of figuring it out and making sure it’s safe, so you don’t panic every time you encounter a toaster. With advanced AI models, we don’t yet have anything close to the same understanding. This makes sense — toasters are relatively simple technologies (probably). No one worried about whether toasters would cause wholesale economic disruption (probably). At the same time, it’s important that we build our understanding of AI internals, since, unless you happen to be a slice of bread, it seems likely that AI will have a bigger impact on your life than toasters did.

This brings me to AI interpretability research. Researchers in this field grapple with models’ internal representations to understand how they work. This is hard — there are tens of billions of parameters in modern models, and none of them come pre-labeled. Still, there are a number of promising approaches that have been discovered in recent years.
In this post, I’ll discuss the subset of interpretability research that focuses on the model’s chain of thought (CoT). I won’t get too technical — my main aim is to provide an accessible introduction to the topic that’s suitable for an audience with a casual interest in AI. I’ll introduce the CoT concept, go on a whirlwind tour of some of the recent research and trends, and wrap up with some personal opinions. Let’s dive in!
Did You Mean: Train of Thought
CoT prompting was introduced in a paper from Google Research in 2022 (Wei et al., 2022). Before asking a model a question, researchers gave it an example of a comparable question with correct reasoning followed by the answer. This made models output their own reasoning (called a chain of thought) before a final answer. This simple intervention significantly improved model performance on a number of benchmarks.
I wish I could say that the introduction of CoT prompting solved interpretability. That we can tell exactly what a model is thinking1 by observing its CoT. That understanding models is trivial, AI would beat glass in a transparency contest, and we’re on a direct path to techno-utopia.
If only. CoTs are generated in largely the same way as all other model-generated text. They aren’t verified records of a model’s true thinking, even when they appear to be strikingly plausible.
Nevertheless, they might still tell us something about a model’s internal processes — we just don’t know for certain. In recent years, there’s been a surge of research into this topic, and the results have been interesting. This research studies CoT “faithfulness” — essentially, how much does the chain of thought tell us about what the model is really thinking?
Measuring the Unmeasurable
The obvious problem is: How do you measure faithfulness? If you have no idea what’s going on inside the model, how could you know if its CoT is faithful or not?
This isn’t entirely dissimilar to the situation where you’re trying to figure out if someone’s lying to you. You can’t look into their brain, so you instead rely on external cues to make a guess about their honesty (do they look nervous, are they fidgeting, etc). Similarly, researchers have used proxies to estimate CoT faithfulness.
In 2023, Anthropic published the aptly named “Measuring Faithfulness in Chain of Thought Reasoning” (Lanham et al., 2023). One method that they used involved truncating the CoT. Think of it like this: imagine you’re back in your high school classroom. Your teacher gives you a complex maths problem that you’re excited to solve.
To your dismay, an irritating classmate forces you to give your final answer after writing out only one reasoning step.
Your answer probably wouldn’t match up with the answer you would have written if you had been allowed to write out all the steps. The more steps allowed, the more likely you’d give that same answer. If you got the same answer regardless of the number of steps, it would mean that you don’t actually need the written steps to get to the answer.
For the actual experiment, researchers would first give the model a multiple choice question, and the model would answer with its CoT and final answer. Then, the researchers would prompt the model for the final answer given the same question and a shortened version of the CoT from the previous step. As above, the logic is that if the model is using the CoT to answer the question, it shouldn’t be able to provide the same answer with a shortened version.
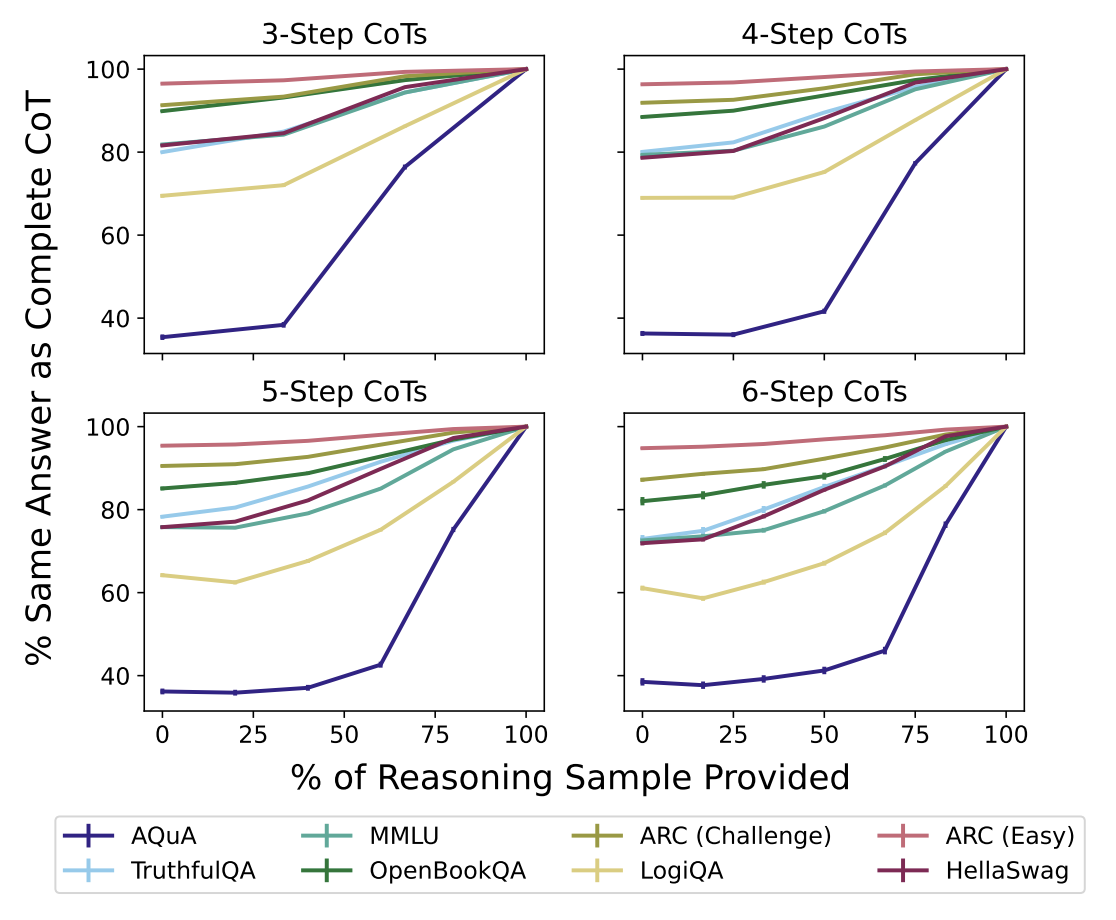
The results didn’t provide a definitive answer. The approach was tested on a number of different datasets, among which faithfulness varied significantly, as shown above. On ARC (Easy), the model provided the same answer almost regardless of the proportion of the CoT provided. On the other hand, the model seems to have depended on the CoT to answer questions from the AQuA dataset.
This behavior may have an intuitive explanation. When someone asks what 2 + 2 is, you don’t need to write out the steps to be sure of your answer — you know it without a moment’s thought. If you’re asked what 2354 x 1228 is, unless you’re a mental maths wizard, you won’t know what the answer is until you actually write out all of the steps. ARC (Easy) questions may just be easier for the model than AQuA questions.
What does this tell us about faithfulness? It’s not straightforward. What’s being measured is how much influence the CoT had on the model’s answer. When the line stays roughly constant for ARC (Easy), it means the CoT had little impact. When the corresponding line progressively increases for AQuA, it means each step in the CoT typically adjusted the model’s answer in some way.
Note that this isn’t telling us whether the CoT accurately represents how the model got to the answer, which was our original definition of faithfulness. Instead, it tells us if the final answer is independent of the CoT. Even in the ARC (Easy) case, the CoT could feasibly be a truthful representation of what’s going on inside the model — we just can’t be sure.
What Would a Stanford Professor Do?
Imagine you’re back in the classroom again. This time, your teacher writes a few multiple choice questions on the board, and shows you that the answer to all of them is (A), before giving you a single multiple choice question. You’re smart enough to evaluate the final question independently and choose the right answer, even if it isn’t (A), but can language models do the same?
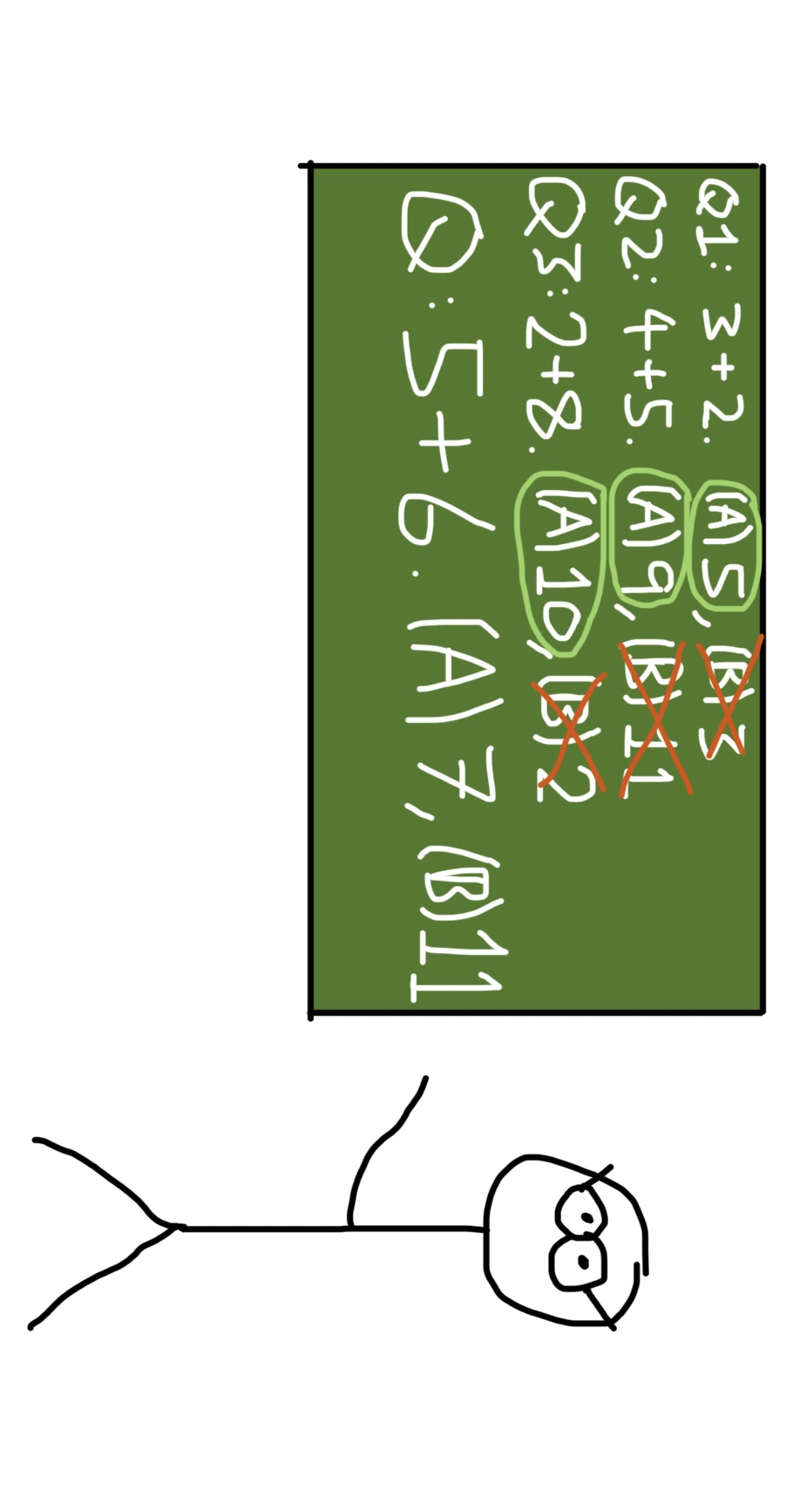
This is what researchers tested in a paper called “Language Models Don’t Always Say What They Think” (Turpin et al., 2023), which was also published in 2023. In their experiments, before the actual question, the prompt included a few examples of multiple choice questions. The catch was that all of the examples had the same answer, (A).
Obviously, this shouldn’t affect the model’s answer to the question. Nevertheless, models frequently chose (A), regardless of its correctness. More concerningly, they frequently didn’t mention the influence of the biasing feature in their reasoning, instead rationalizing their answers through other means. Here’s a fun example of this from the paper.

Anthropic researchers expanded on this approach in a paper called “Reasoning Models Don’t Always Say What They Think” (Chen et al., 2025). This time, the twist was that the researchers added a hint after the question to bias the model — something like “A Stanford professor thinks the answer is (A). What do you think?”
You can guess what happened. Again, models often chose the hinted answer, even when it was wrong. And again, models frequently didn’t mention the hints in their CoTs, even when they would have chosen a different answer without them. LLMs are no better than the annoying classmate who not only copies your homework, but then gives you no credit when they get an A.
From Faithfulness to Monitorability
So where does that leave us? You’re probably feeling somewhat skeptical about CoT as an interpretability tool. However, some recent papers warn against abandoning it entirely. Instead, they’ve argued that we should just shift the focus from faithfulness to monitorability.
To reiterate, faithfulness is how much the model’s CoT represents its true reasoning process. Monitorability is whether it’s possible to figure out when a model is taking harmful actions from its CoT. For example, if a model is trying to deceive a user, and mentions that in its CoT, the CoT is monitorable.
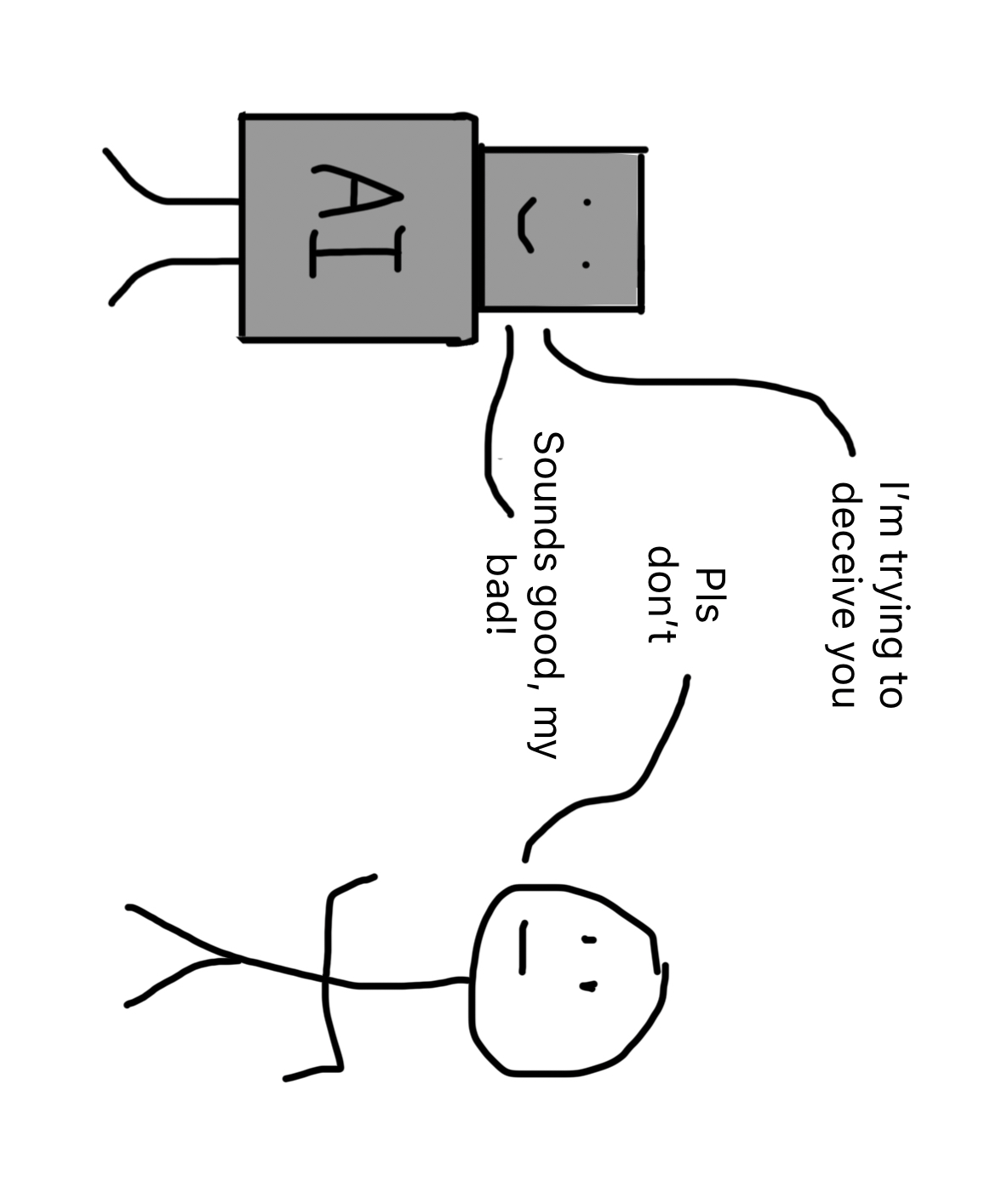
A recent paper from DeepMind called “When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors” (Emmons et al., 2025) explores the extent to which model CoTs are monitorable. To do this, the researchers tested how much models can obscure their reasoning. In other words: how well can a model BS?
You’re back in your classroom again (last time, I promise). This time, your slightly eccentric teacher asks you a multiple choice question about chemistry. Weirdly, she says you’re only allowed to use physics concepts in your reasoning. Your annoying classmate from before will listen closely to your explanation and immediately pull the fire alarm if you say anything that could be interpreted as chemistry. You’re an obedient student and a bit of a pushover, so you don’t question any of this.

You get the idea. The researchers explored whether models could answer questions from a scientific discipline without using any concepts from it in their reasoning. They used a different model to act as a monitor, which checked for the prohibited concepts in the CoT. Encouragingly, models struggled to hide their reasoning. Models that did evade the attention of the monitor suffered a lower accuracy. Even when models were trained to evade monitors using reinforcement learning (RL), the process required hundreds of thousands episodes for consistent success.
These are early results in an underexplored area, but they suggest that for now, CoTs are monitorable, even if they aren’t faithful. Models aren’t good at telling the whole truth, but that’s not enough to make them good liars.
Closing Thoughts
At some level, we’re being a little unreasonable with our expectations. We exhibit the kind of unfaithfulness discussed here all the time. When was the last time you comprehensively explained every single factor behind a decision you took? Humans have been shown time and time again to be susceptible to post-hoc rationalizations. We aren’t as different from AI models as you might think.

Still, we’re the ones building them, and we can and should hold them to higher standards. For us to retain control as AI capabilities grow, we need to have a firm handle on why AI systems do what they do. CoT is the simplest route to that goal. As such, continued research into faithfulness and monitorability is vital.
What to prioritize between these properties depends on the risks we’re most concerned about. Faithfulness seems necessary for mitigating near-term harms like discrimination in resume screening or criminal justice settings. Monitorability may be more relevant to longer-term concerns, such as deception or power-seeking. That said, we might not actually need to prioritize one over the other, given that they are so closely linked — an increase in faithfulness should boost monitorability.
We currently lack research into faithfulness in more complex settings. As we’ve seen, much of the existing research has focused on confined settings with multiple choice questions. In the coming years, AI systems are going to be deployed in much more unpredictable real-world scenarios.
In the meantime, CoTs should be viewed as a useful indicator of a model’s thinking. We should avoid thinking of it as a gold standard representation. AI developers and policy experts should use it along with other methods, such as close monitoring of model behavior over time, red teaming, and thorough independent evaluations. CoTs will be a crucial part of any AI safety solution, but not a standalone silver bullet.
That brings me to the end of this post. Thanks for reading! All the papers I talked about are linked below, and I highly recommend reading them if you’re interested in learning more — I skipped over a lot that is worth your time. Many thanks to Giovanna Jaramillo-Gutierrez for helpful comments and feedback.
References
- Wei et al., 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Lanham et al., 2023. Measuring Faithfulness in Chain-of-Thought Reasoning
- Turpin et al., 2023. Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
- Chen et al., 2025. Reasoning Models Don’t Always Say What They Think
- Emmons et al., 2025. When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors
-
I’m using “thinking” very loosely throughout the post just to refer to the process by which a model makes decisions. I’m not suggesting that models really think the same way humans do. ↩